#RAG DeepSeek+本地知识库部署
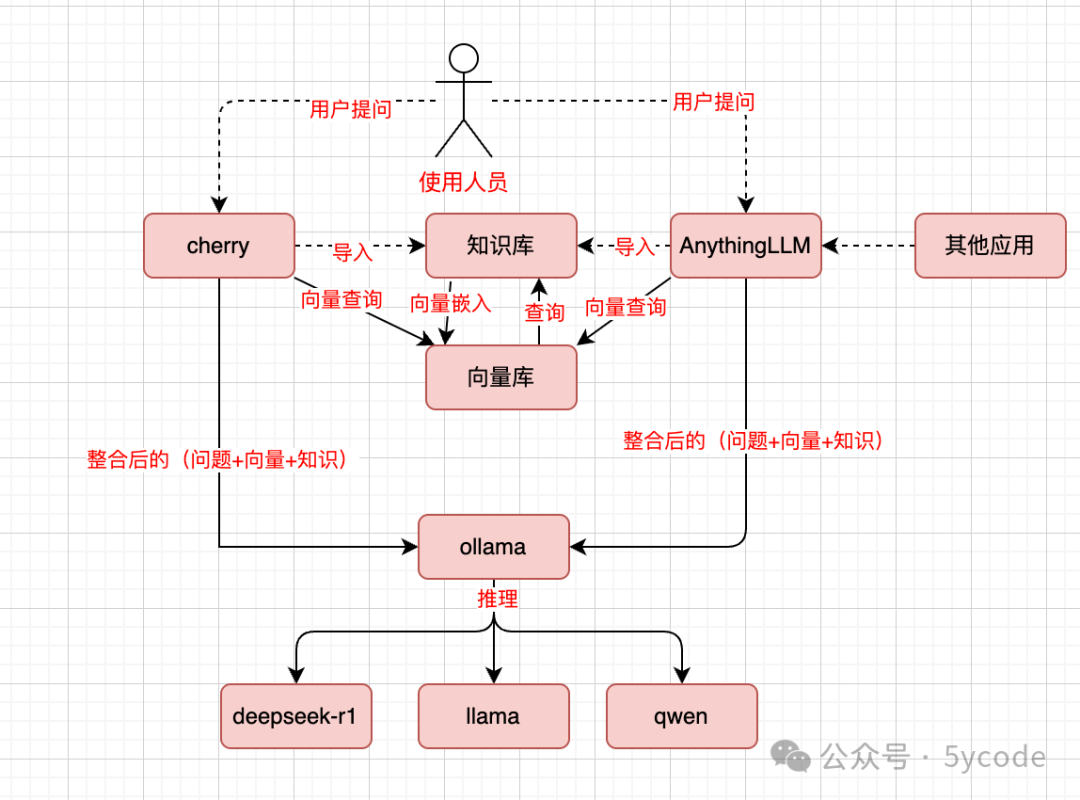
什么是RAG系统? 简而言之,RAG系统通过整合大型语言模型(LLM)与外部知识源,实现了能力的显著提升。这种整合机制使得模型能够动态地引入相关信息,从而生成既连贯又准确,且与上下文高度相关的回应。RAG系统的核心组件包括:
检索器(Retriever):负责从外部知识库中高效提取与查询相关的数据。 生成器(Generator):利用LLM将检索到的信息融合,生成接近人类表达的回应。 通过结合这些组件,RAG系统能够提供基于实时数据而非仅依赖预训练知识的答案,有效解决了预训练知识可能迅速过时的问题以及大模型幻觉问题。
#总体数据流程
#1. 安装 ollama
https://github.com/ollama/ollama 直接安装
curl http://localhost:11434/. check ollama running
https://ollama.com/library/deepseek-r1 模型仓库,类似 dockerhub
#2. 拉取模型
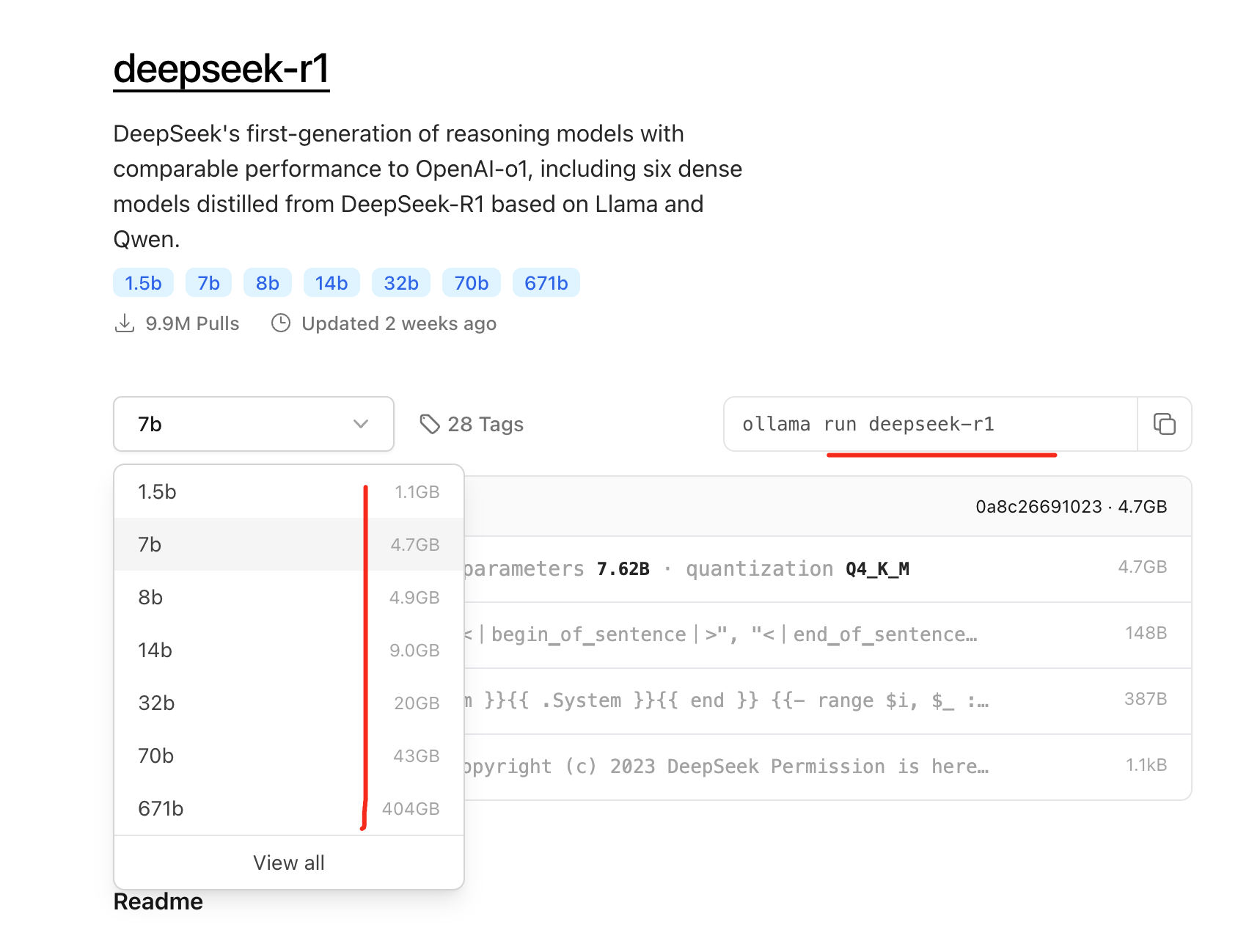 ollama run deepseek-r1:8b
看好内存大小,也可以 deepseek-r1:32b
ollama run deepseek-r1:8b
看好内存大小,也可以 deepseek-r1:32b
如果拉不下来,速度变慢、卡住,关闭,重新拉(会续传)
剩余参考这篇文章 : https://mp.weixin.qq.com/s/IKoBga2iKfpkdD4Qgy8iLg
#3. ollama pull bge-m3 下载向量化模型, 用来把知识库向量化
#4. 安装 cherry-studio 借助它 ui 页面操作
#下载 cherry studio
根据自己的环境下载 cherry studio
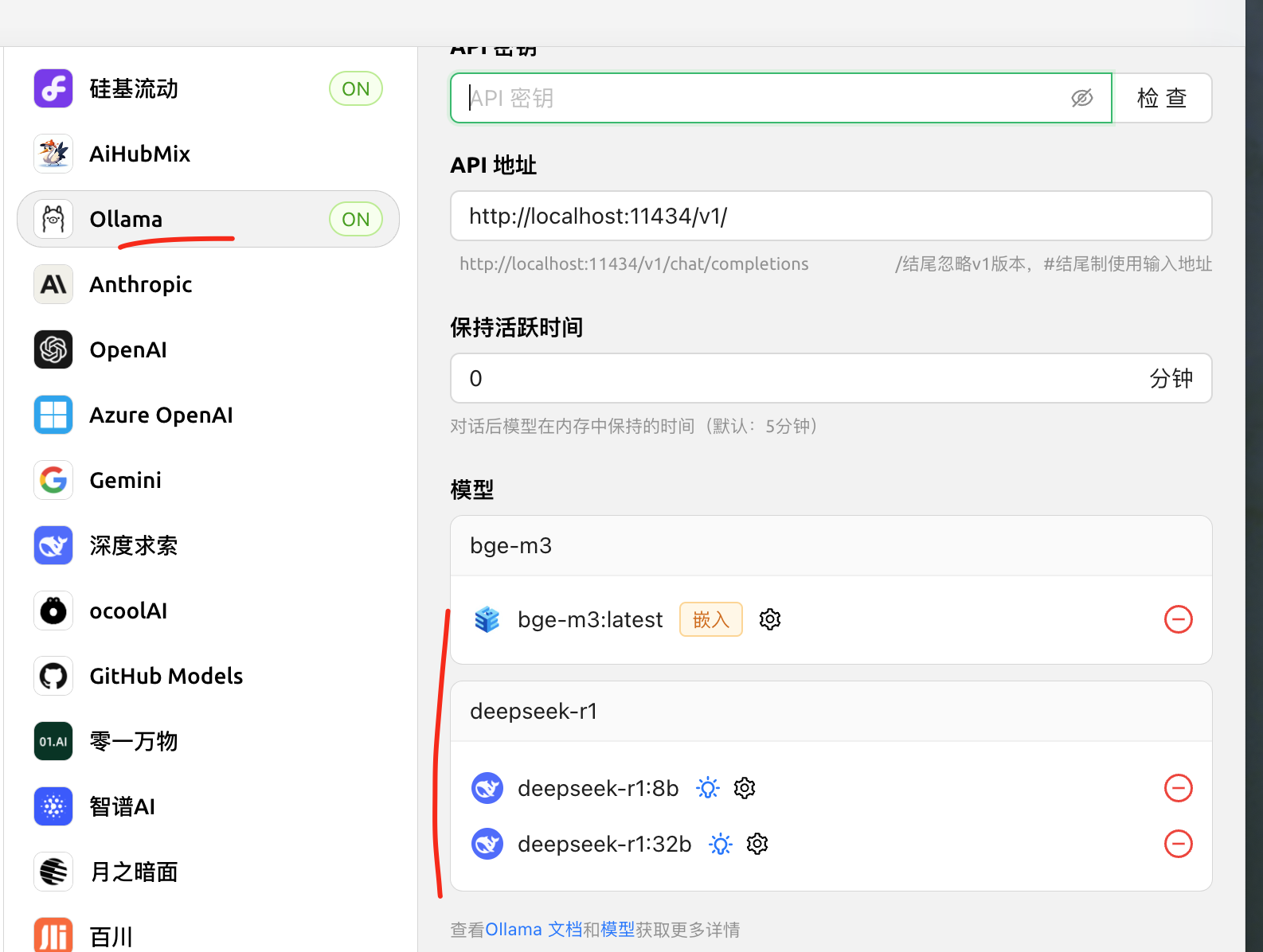
#配置本地 ollama
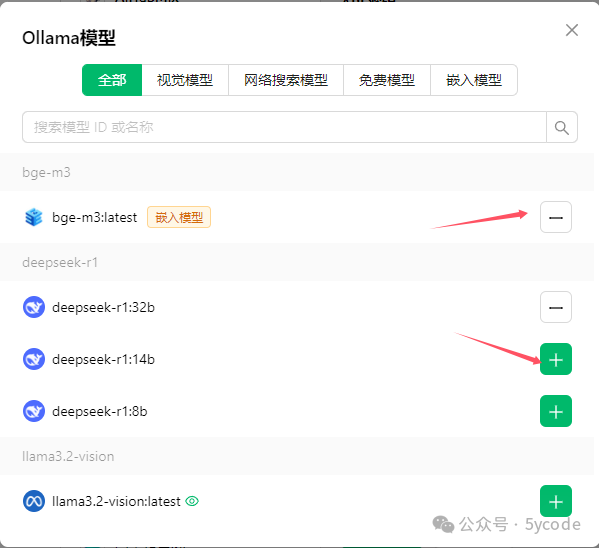
#操作步骤:
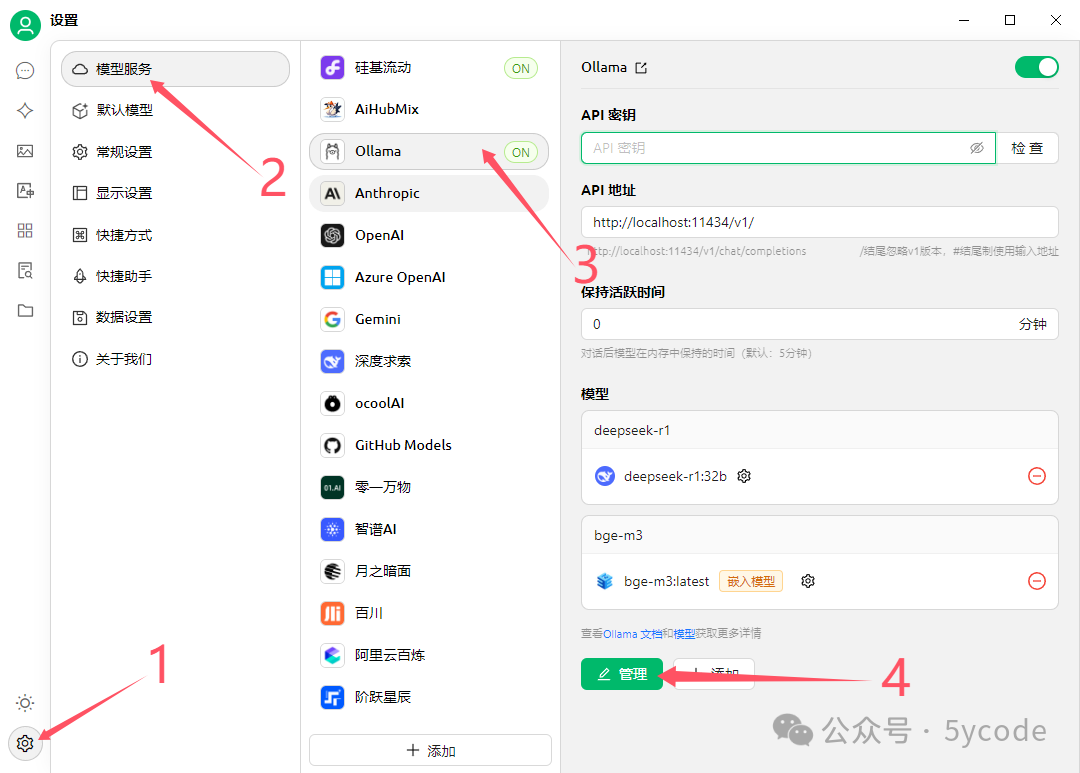
找到左下角设置图标 选择模型服务 选择 ollama 点击管理 点击模型后面的加号(会自动查找到本地安装的模型) 减号表示已经选择了
#知识库配置
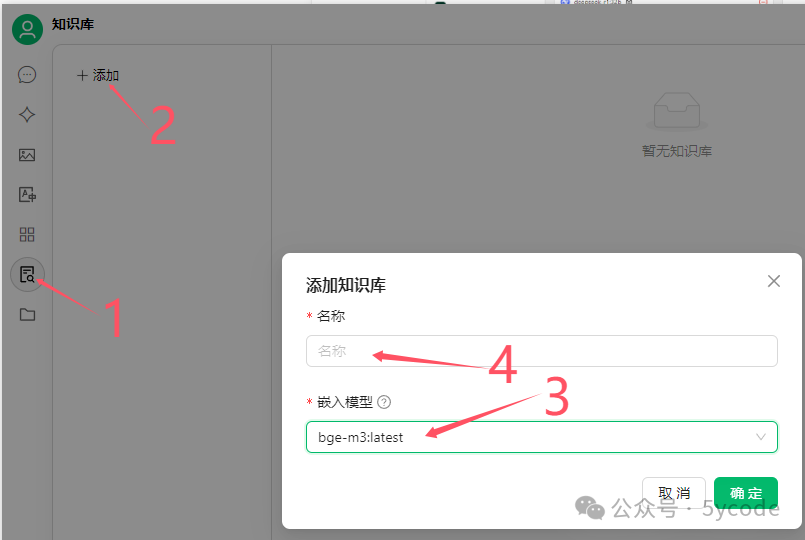 1.选择知识库
2.选择添加
3.选择嵌入模型
4.填写知识库名称
1.选择知识库
2.选择添加
3.选择嵌入模型
4.填写知识库名称
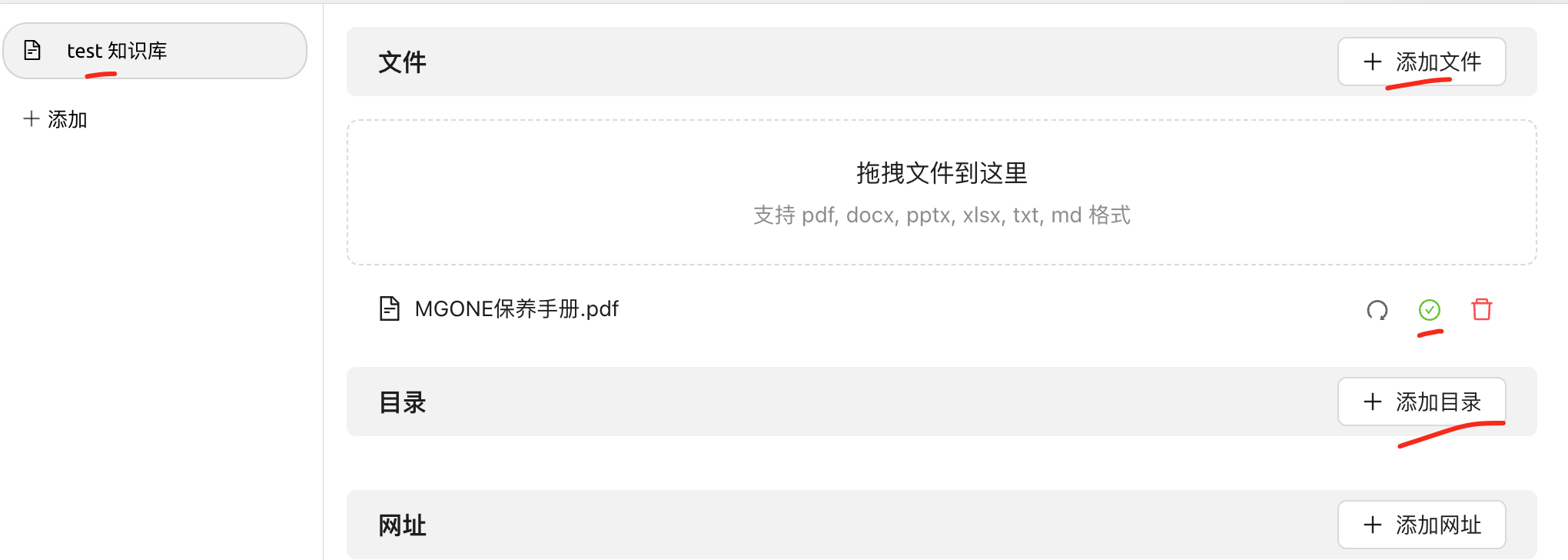
#添加知识文档
cherry 可以添加文档,也可以添加目录(这个极其方便),添加完以后出现绿色的对号,表示向量化完成。
#搜索验证
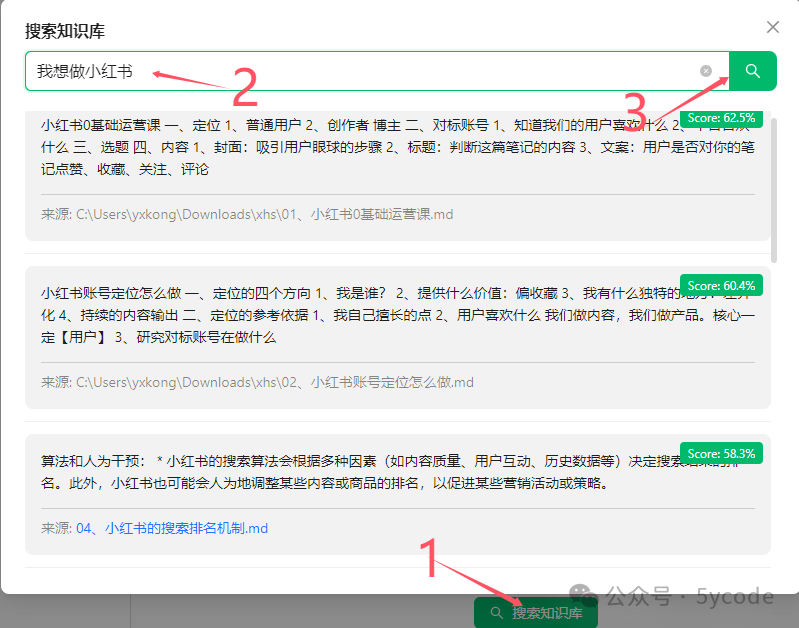 点击搜索知识库
输入搜索顺序
点击搜索 大家可以看下我搜索的内容和并没有完全匹配,不过已经和意境关联上了。
点击搜索知识库
输入搜索顺序
点击搜索 大家可以看下我搜索的内容和并没有完全匹配,不过已经和意境关联上了。
#大模型处理
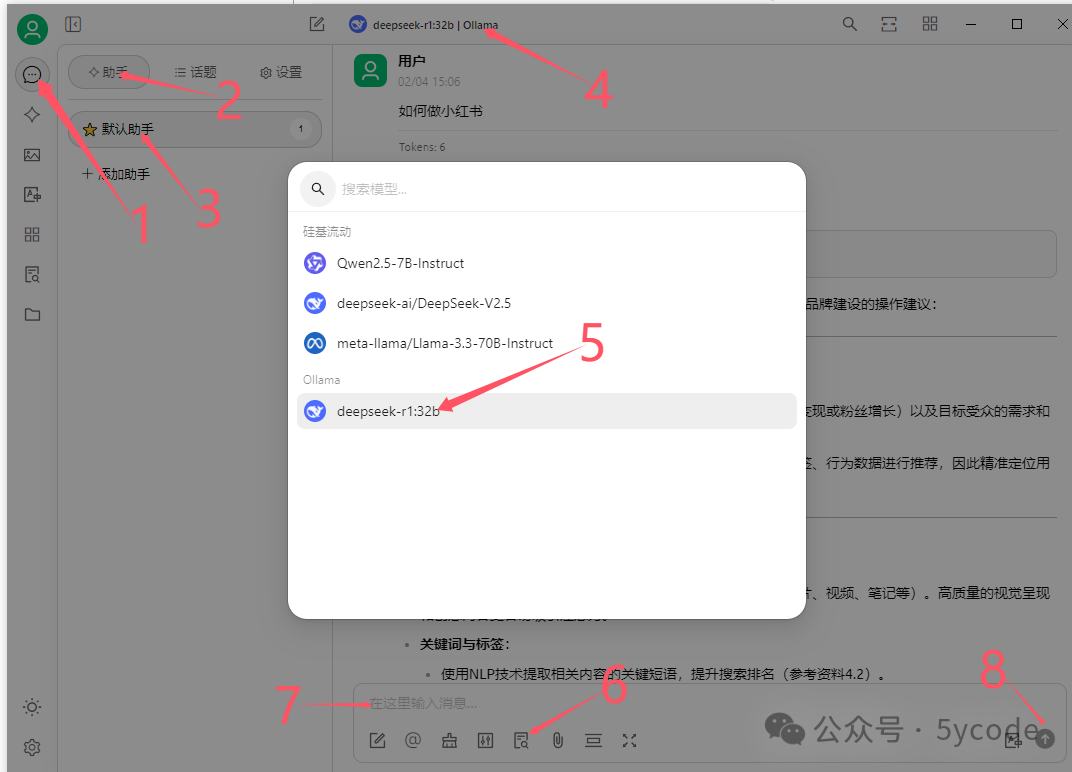 点击左上角的聊天图标
点击助手
点击默认助手(你也可以添加助手)
选择大模型
选择本地 deepseek,也可以选择自己已经开通的在线服务
设置知识库(不设置不会参考)
输入提问内容
点击左上角的聊天图标
点击助手
点击默认助手(你也可以添加助手)
选择大模型
选择本地 deepseek,也可以选择自己已经开通的在线服务
设置知识库(不设置不会参考)
输入提问内容
#发问
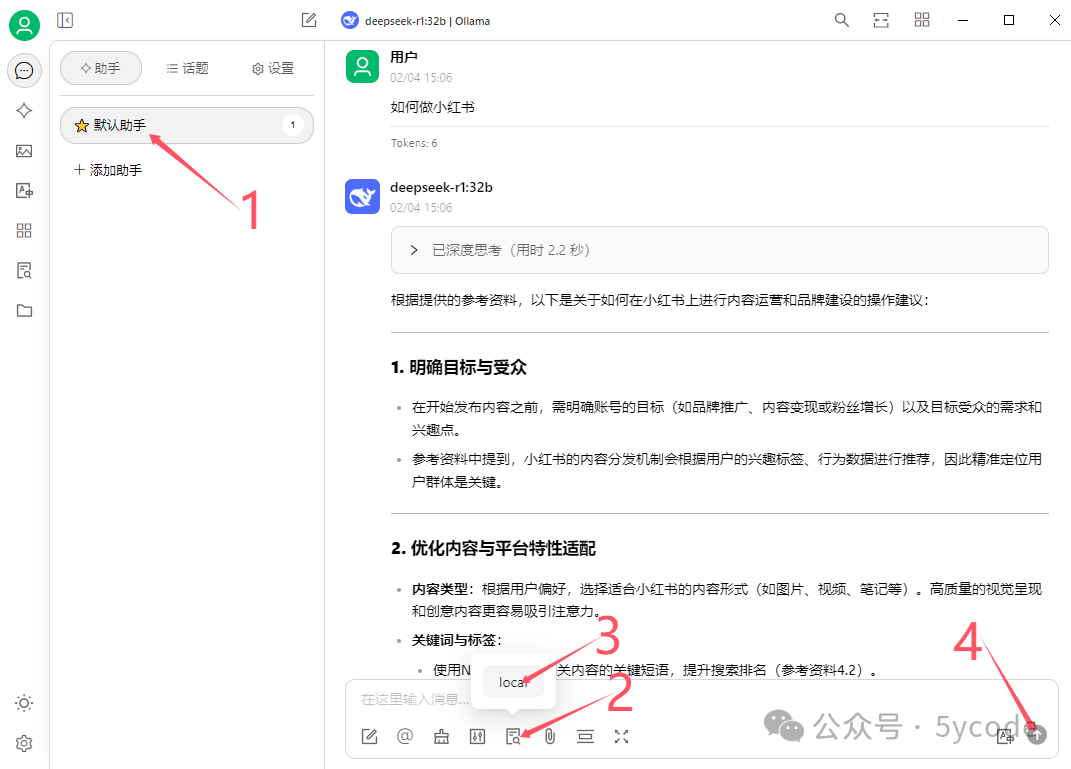
大家可以看到 deepseek 已经把结果整理了,并告诉了我们参考了哪些资料。
#满血版 API
自己本地模型体验后,可以切换到硅基流动 在线 api ,感觉明显质量不同...😄
如果你的知识库有隐私数据,不要联网!